
As mentioned in the previous post, a highlight of the project I participated in over the past five weeks was the three-day workshop that we organized at STIAS towards the end of October.
The purpose of the workshop was to bring together a small group of computer scientists, physicists, mathematicians and philosophers around the broad theme of “the nature of randomness”. Each of our respective fields brings its own angle on the problem, with a specific language for formulating associated questions, judging which are most important, and a set of techniques to approach them. In computer science we use entropy, complexity theory and pseudo-randomness; physicists have access to randomness through the fundamental laws of nature; philosophers introduce subtle distinctions between probability, chance, and intrinsic or subjective randomness. The presence of any such framework is a prerequisite to progress: it enables to formulate research problems, develop appropriate methodologies, and obtain results. But any framework also sets implicit boundaries and runs a risk of turning into a dogma, according to which “valid” or “important” questions and results are judged. From my perspective, if there is any respect in which I would dare deem the workshop a success it is precisely in the barriers it helped bring down. The wide-ranging talks and participants forced me to take a broad perspective on randomness and question some of the most deeply ingrained “certainties” that underlie my research (such as a firm — though baseless — belief that the Copenhagen interpretation is the only reasonable interpretation of quantum mechanics worthy of a practicing scientist). This questioning was only made possible thanks to the outstanding effort put in by all participant to deliver both accessible and stimulating talks as well as to actively engage with each other; I cannot thank them enough for making the workshop such an enlightening and interactive experience.
It seems impossible to do any justice to the ideas developed in each of the talks by discussing them here, and in doing so I am bound to misrepresent many of the speaker’s thoughts. For my own benefit I will still make an attempt at listing a few “take-away” messages I wish to keep; obviously all idiocies are mine, while any remaining insight should be attributed to the proper speaker.
The opening talk was delivered by Valerio Scarani, who started us off with a personal take on the history, and future, of “Quantum randomness and the device-independent claim“. The “irreducible presence” (much more on this “irreducibility” will be discussed in later talks!) of randomness in quantum mechanics is usually attributed to the Born rule, which states that the probability of obtaining outcome 
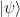



Extract from Born’s paper
(Incidentally, see this paper by Aaronson for interesting consequences of instead using a 
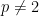
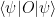

Indeed Einstein’s immediate reaction to Born’s paper is immortalized in his famous letter to Born from November 1926:
Quantum mechanics calls for a great deal of respect. But some inner voice tells me that this is not the right track. The theory offers a lot, but it hardly brings us closer to the Old One’s secret. For my part at least, I am convinced He doesn’t throw dice.
And thus started one of the most obscure periods in human thought… A famous anecdote along the route (though again, this was news to me) is given by von Neumann’s valiant attempt at establishing a rigorous “no-go” theorem for “hidden variables”, thereby proving the unavoidable resort to some form of uncertainty. Unfortunately it turned out that von Neumann’s theorem placed unreasonable assumptions on the hidden variable models to which it applied, making it all but inapplicable. Pressing ahead, skipping over Einstein, Podolsky and Rosen’s unfortunate account of (non-)locality in quantum mechanics, it is only with Bell’s 1964 paper demonstrating that the existence of local hidden variable theories for quantum mechanics could be experimentally tested that the debate was finally placed on firm — or, at least, in principle decidable — grounds. Indeed the major contribution of Bell’s work was to establish observable consequences for the existence of any hidden variable model for quantum mechanics — under the important assumption, to be further discussed in the talk by Ruediger Schack, that the model be local. Bell’s result had an immediate impact, prompting one of the most interesting experimental challenges in the history of physics. This is because there was no consensus as to what the outcome of the experiment “should” be, and proponents of a breakdown of quantum mechanics (at least in the regime concerned in Bell’s test and its subsequent refinement by Clauser et al.) stood on an equal footing with advocates of fundamental laws of nature that are non-local and probabilistic (of course either camp was dwarfed by the much larger number of physicists who simply considered the question irrelevant for the practice of their work… luckily for the progress of science, which would not have benefited much from stalling for two decades). And indeed early experiments went both ways, with “conclusive” results pointing in either direction obtained on the West and later East coasts of the US. The quest was brought to a climactic conclusion with Aspect’s experiments in Orsay in 1981-82, which conclusively handed the podium over to the Bell camp (how conclusively, however, you can judge from the amount of — justified — attention generated by the most recent experiments in Delft).
The history is fascinating (anyone can suggest a good, entertaining, informed and opinionated account?, but we should move on. Following the speaker’s lead, let me scoot ahead to modern times and the birth of device independence. This is usually attributed to the 1998 “UFO” by Mayers and Yao, who were the first to make a fundamental observation: that a complete quantum mechanical description of a black-box device, including its state and the measurements it performs on the state, can, in some cases, be inferred from the classicalinput-output measurement statistics it provides — provided one is willing to make one structural assumption on the device: that it has a certain bipartite structure, i.e. is composed of two systems on which certain (unknown) measurements can be independently performed (in their paper Mayers and Yao call this a “conjugate coding source”). The reason I qualify this result of “UFO” is that, although the motivation behind it is clear (obtain a proof of security for BB’84 that would be robust to imperfections in Alice’s photon generation device), the technique has no precedent. It is certainly natural to attempt to certify Alice’s device by performing some kind of tomography, but from there to seeing how a bipartite structure could be leveraged to obtain the result in such strong terms! (Note that, without a priori information on either the state or the measurements being performed, “tomography” cannot lead to any meaningful conclusion.) Certainly the authors must have been influenced by their intense ongoing work in proving security of QKD, and the intuition obtained from the security proofs. Still — quite a feat!
A second respect in which the Mayers and Yao paper can be qualified of “UFO” is that in spite of the conceptual breakthrough that we now recognize it for it was all but ignored following the years after its publication. One reason may be that it was published in the most obscure of conferences (proceedings of FOCS, anyone?). A more reasonable explanation is that the math in the paper is hard to follow: the notation is rather heavy and little intuition is given. From a QKD practitioner’s point of view, this is completely foreign territory; the techniques used bear very little resemblance to the techniques used at the time to prove security of QKD protocols and analyze their performance. Finally the result does suffer from one important drawback, which is that it is non-robust: Mayers and Yao were only able to characterize devices which perfectly reproduce the required correlations, but did not give any statement that tolerates 

The second birth (in terms of explosion of attention and interest) of device independence can be attributed to the 2005 paper by Barrett, Hardy and Kent. Although I cannot speak for them my impression is that the main motivation for their work was foundational; indeed the central question they ask is the extent to which the correlations that are checked by the users in all QKD protocols are sufficient by themselves: that is, can quantum mechanics be thrown out, and security derived only from these correlations? After all, from the point of view of the users the protocol is completely classical, and its security can also be defined classically, as the maximum probability with which an eavesdropper can “guess” the key that is eventually produced. Thus even if an implementation of the protocol may rely on quantum mechanical devices, its mode of operation, and security, can be formulated purely using statements about classical random variables. Barrett et al. showed that security could indeed be established in a model that is broader than quantum mechanics, assuming only the existence of joint probability distributions describing the input-output behavior of the devices and a potentail adversary, and the assumption that these distributions satisfy the no-signaling principle: outputs of either of the three systems do not depend on inputs chosen by any other party. Their work builds upon a strong line of research in non-locality (e.g. the introduction of the famous “PR boxes” by Popescu and Rohrlich a decade earlier), and it had one immense merit, which helps explain its impact: by completely “stripping out” all the messy details that obscured existing security proofs for QKD they managed to restore the intuition behind the security of QKD (see Ekert’s paper for a beautifully succinct formulation of that intuition), showing how that intuition could be formalized and lead to an actual proof of security — and this, under arguably stronger terms than the existing ones! Thus the link between Bell violation and security was finally expressed in its purest form. The beautiful paper was immediately followed by an intense line of works exploring its consequences, deriving device-independent proofs of security for QKD which achieved better and better rates under weaker and weaker assumptions (for instance on noise tolerance, or on the types of attacks allowed of the adversary). This is a very long story, with much more to say (check out the fourth slide from Valerio’s talk!), but once again it is time to move on.
In the second part of his talk Valerio gave us his four main “concerns” regarding device independence. In Valerio’s opinion these “concerns” are important assumptions that underlie device-independent cryptography — assumptions that are reasonable as they are recognized as such, but could undermine the field if not made explicit and discussed upfront.
The four concerns are the following:
- No-signaling (the physicist’s concern): It is usually claimed that device-independent protocols are secure “provided the no-signaling condition is satisfied”. But what does this mean? That no information can travel in-between the two devices within the amount of time that elapses between the moment at which the choice of basis is made, and the moment at which the device produces an outcome. There is a fundamental ambiguity here: how is the time of “basis choice” defined? Does it correspond to the moment when the experimenter first sets her mind on a particular setting (whether and how much “liberty” she really has in this choice is a different issue, the so-called “free will loophole”)? Or does it correspond to the moment at which the device is “informed” of that choice, as the experimenter presses the appropriate button? Or is it really only when the information reaches the photon polarizer located inside the device? The same questions can be asked for the time of “outcome production”: when exactly is the outcome determined? When the photon hits the receptor? When the outcome is displayed on the device? When the experimenter stares at it? Once more this is a subtle issue, related to the measurement problem in quantum mechanics and which components of the system are modeled as quantum and potentially in coherent superposition, and which are classical and “decohered”. Going from the one to the other requires an application of the Born rule, and it is not clear at what level this should take place.
- Input randomness (the information-theorist’s concern): This is an important point, which I think is now well-understood but was certainly not when procedures for device-independent randomness certification were first being discussed. The question is how the randomness present in the input to the devices should be quantified — succinctly, “random to whom”? The crucial distinction is as follows: the input should be random-to-device, whereas the output should be random-to-adversary. That it is possible to transform the one to the other is, to a great extent, the miracle of device-independent randomness certification: even if the inputs are completely known to a third party, and even if that party is quantum and shares entanglement with the devices, as long as the inputs are chosen independently from the devices (very concretely, their joint state, when all other parties are traced out, is in tensor product form), the outputs produced are independent from the adversary (same formalization, but now tracing out the devices). For those interested in this issue I highly recommend having a look at the “equivalence lemma” of Chung, Shi and Wu (Lemmas 2.2 and 5.1 here).
- Detection loophole (the hacker’s concern): arguably this is the most openly discussed of Valerio’s four concerns, and I won’t get into it too much. The problem is that current state-of-the-art photon receptors have low efficiency, and more often than not fail to detect an incoming photon. Thus in order to claim that the statistics observed in an experiment demonstrate the violation of a Bell inequality one has to resort to the “fair sampling assumption”, which states that no-detection events occur independently from the basis choice provided to the device. For most experiments this assumption seems reasonable, but in the context of device independence, where one often claims that the devices “have been prepared by the adversary”, it is certainly not so. Nevertheless we may hope that continued experimental progress (or different measurement techniques, such as the use of diamonds in the Delft experiment) will eventually eliminate this loophole.
- (In)determinism (the philosopher’s concern): what if randomness simply doesn’t exist? Two of the three most widely debated attempts at making sense of probabilities in quantum mechanics, the many-worlds interpretation and Bohmian mechanics (the third being the Copenhagen interpretation), posit determinism at some level: in many-worlds, there is determinism for a being who can observe all universes; in Bohmian mechanics there is determinism for a “nonlocal” being who has access to all hidden variables. As Valerio pointed out, however, these need not be serious issues, as what we really care is that the randomness in the outputs produced, or the security of the key, are measured with respect to a being in our universe: indeed it should not be of any concern that the random bits are “determined” by some hidden variables if access to these hidden variables requires prior knowledge about the whole state of the universe.
There are a lot of valuable take-home messages from the talk. Valerio ended his talk by making the observation that while the violation of Bell inequalities implies the presence of randomness the converse is not necessarily true… This in turn prompts me to ask what really are the fundamental assumptions that are necessary and sufficient to guarantee randomness. Device independence, as it is now understood, relies on locality: if it can be assumed that certain events take place at positions that are isolated in space-time then certified fountains of randomness follow. But what if we are unsatisfied with the assumption — how necessary is it really? An interesting variation is to certify randomness based on the contextuality of quantum mechanics; this is a challenging setting both from an experimental and theoretical points of view and I expect it to receive more attention in the future. But there are possibilities that take us in completely different directions; as an obvious example pseudo-randomness offers the possibility of certifying randomness based on computational assumptions. Are we on the right track — what if we were to take the irreducible presence of randomness as an assumption, what consequences would follow? (See Yevgeniy Dodis’ talk, to be discussed later, for some consequences in cryptography).

Thanks for the very nice post Thomas, looking forward to the coming ones 🙂
But… what’s the fourth concern regarding device independence?!
Ah, good point, thanks 🙂 Apparently this got cut off when I created the post; I hope it didn’t happen in too many places! The missing concern is the detection loophole, and I put it back in.